O que o caso do LinkedIn nos ensina sobre segurança de dados
Casos de vazamento não são novos nem raros, mas muitas pessoas não sabem o que está por trás nem o que fazer sobre isso
:format(webp))
Ninguém espera que um conjunto de informações seja agrupado em um banco de dados (Getty Images/Reprodução)
Bússola
Publicado em 17 de julho de 2021 às 11h00.
Por Cláudio Dodt*
No começo de 2021, um megavazamento de dados expôs mais de 220 milhões de informações de brasileiros, incluindo CPF, foto de rosto, endereço, telefone, e-mail, score de crédito, salário e outros dados pessoais. Em um caso mais recente, o LinkedIn, a maior rede profissional da internet, foi acusado de ter exposto de forma indevida os dados de mais de 700 milhões de usuários, o que seria o maior vazamento já sofrido pela empresa.
Mas realmente ocorreu mais um vazamento no LinkedIn?
Conforme reportado pela empresa RestorePrivacy, um cibercriminoso passou a ofertar os dados de 700 milhões de usuários do LinkedIn em um conhecido fórum hacker. A amostra do vazamento, incluía dados de pelo menos 1 milhão de pessoas e continha informações como endereços de e-mail, nome completo, números de telefone, endereços físicos, registros de geolocalização, gênero, experiência profissional, detalhes sobre contas em outras redes sociais, dentre outros.

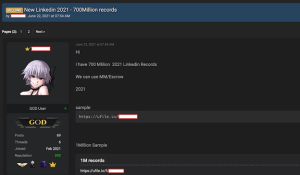
Cibercriminoso colocando dados de usuários do Linkedin em fórum hacker (RestorePrivacy/Divulgação)
Como a própria página de informações do LinkedIn afirma que a rede social atualmente possui mais de 756 milhões de usuários, podemos estimar que supostamente o vazamento teria afetado 92% dos inscritos. Porém, cibercriminosos não são uma fonte de informação muito confiável, então o próprio time da RestorePrivacy fez uma análise cruzada de parte dos registros contidos na amostra, e aparentemente esses batem com informações de pessoas reais. O que valida que realmente ocorreu um vazamento, certo? Bem, não exatamente.

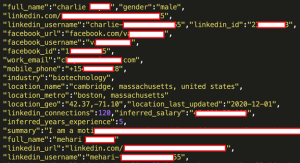
Amostra de dados vazados do Linkedin (RestorePrivacy/Divulgação)
E como os dados teriam sido vazados?
De acordo com informações obtidas diretamente do cibercriminoso que ofertou os dados, a fonte do vazamento supostamente foi uma falha de segurança na API do LinkedIn, que é uma Interface de Programação de Aplicação rotineiramente usada, por exemplo, para transferir dados entre diferentes sistemas, aplicações ou websites.
Entretanto, em uma declaração oficial sobre o caso, o LinkedIn afirma que nem todos os dados poderiam ter sido obtidos através da API, e que o mais provável é que as informações tenham sido coletadas através de outras fontes como, por exemplo, por meio de técnicas de “Raspagem de Dados”, ou Scraping, que é uma forma sistematizada de se agrupar informações publicamente disponíveis, o que pode ser feito no próprio LinkedIn ou em outras redes sociais e serviços similares.
Scraping não é hacking! Entenda
Partindo do princípio de que os dados foram obtidos através de Scraping, é importante entender um fato simples: não houve hacking, e nesse caso, o LinkedIn não foi invadido por conta de uma falha na sua API.
Quando um usuário compartilha publicamente informações em uma determinada rede social, é razoável presumir que esta pessoa não se importa que esses dados sejam encontrados por outros usuários, afinal, é exatamente esse o objetivo, compartilhar informações e ter interações. O que acontece é que ninguém espera que um conjunto de informações — muitas vezes coletadas de fontes diferentes — seja agrupado em um banco de dados muito bem-organizado, fácil de pesquisar, e comercializado em fóruns da darknet e outros locais igualmente nefastos da internet.
E como evitar o Scraping?
Primeiro, você precisa entender que qualquer informação publicamente disponível na internet pode ser alvo de Scraping. Não importa se o dado está em uma rede social, em um site pessoal, ou em um arquivo PDF, se a informação é publicamente acessível, ela pode ser coletada e agrupada. É claro, redes sociais como o próprio LinkedIn não compactuam com esse tipo de coleta, pelo contrário, é algo considerado uma violação dos termos de serviço e que trabalham ativamente para evitar que ocorra.
Mas se você não quer ser mais uma vítima do scraping, existe uma forma bem simples de evitar sua ocorrência: nunca compartilhe publicamente informações que você não gostaria de tornar de conhecimento público. Muitas vezes, quando lidamos com questões relacionadas à segurança, especialmente se isso envolve um vazamento, tendemos a esquecer que o próprio usuário tem em suas mãos o poder de evitar situações indesejadas.
No caso das redes sociais, existe a possibilidade de, por exemplo, restringir quem pode ver determinadas informações como o e-mail ou número de telefone, e também é possível limitar as postagens para grupos específicos com outros usuários que já fazem parte da sua rede pessoal. É importante lembrar que isso reduz a possibilidade de scraping, mas não o evita completamente. Se você não quer correr riscos de uma determinada informação se tornar alvo de uma coleta indesejada, a única saída confiável é não compartilhar.
Por que esses dados coletados de maneira ilegal são tão valiosos?
Independentemente de ter ocorrido um vazamento ou apenas mais um data scraping, o conjunto de dados que estava à venda na darknet inclui uma série de informações que cibercriminosos e outros golpistas adorariam obter.
Por exemplo, essas informações poderiam facilitar tentativas de phishing, roubo de identidade, e todo tipo de ataque baseado em engenharia social. Basicamente esse conjunto de dados “vazados” formam um perfil básico de uma vítima e isso efetivamente facilita a execução de diversos ciberataques.
Dessa forma, é importante estar alerta contra possíveis tentativas de golpe, e redobrar a atenção às funcionalidades básicas de segurança que já existem em redes sociais e outros serviços como, por exemplo, habilitar a autenticação multifator.
O LinkedIn pode ser responsabilizado por esse vazamento?
Respondendo de forma direta: não, uma rede social como o LinkedIn não pode ser responsabilizada por um caso de data scraping, afinal, como já mencionado, foi o próprio usuário quem decidiu compartilhar publicamente a informação.
É claro, sempre existe a remota possibilidade do cibercriminoso ter falado a verdade, e dos dados terem sido obtidos através de uma falha de configuração em uma API. Nesse cenário, sem dúvida, a empresa poderia ser responsabilizada, inclusive nos termos de leis e regulamentações de proteção de dados pessoais como a LGPD e a GDPR.
De toda forma, esse é mais um aviso: segurança e proteção de dados não podem depender exclusivamente do fornecedor do serviço, o usuário sempre tem um papel importante, que muitas vezes acaba sendo fundamental para evitar que os dados jorrem de maneira indesejada pela internet. Da mesma forma que é impossível colocar o gênio de volta na garrafa, é impossível “desvazar” dados.
*Cláudio Dodt é sócio da Daryus Consultoria e especialista e evangelista em Segurança da Informação e Proteção de Dados.
Siga a Bússola nas redes: Instagram | LinkedIn | Twitter | Facebook | Youtube
Veja também

:format(webp))
:format(webp))
:format(webp))
:format(webp))

:format(webp))
:format(webp))
:format(webp))
:format(webp))